0
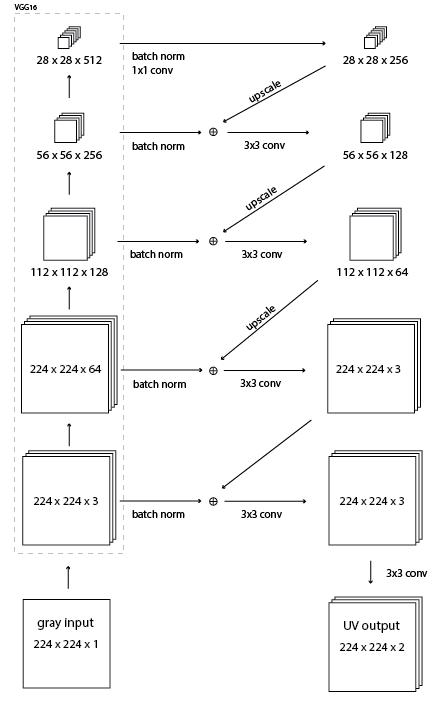
this image이라는 모델을 만들려고합니다. 다음은 관련 코드입니다.이미지를 입력하고 출력 할 때
{kind=link}
base_model = VGG16(weights='imagenet')
conv4_3, conv3_3, conv2_2, conv1_2 = base_model.get_layer('block4_conv3').output,
base_model.get_layer('block3_conv3').output,
base_model.get_layer('block2_conv2').output,
base_model.get_layer('block1_conv2').output
# Use the output of the layers of VGG16 on x in the model
conv1 = Convolution2D(256, 1, 1, border_mode='same')(BatchNormalization()(conv4_3))
conv1_scaled = resize(conv1, 56)
.
.
.
conv5 = Convolution2D(3, 3, 3, border_mode='same')(merge([ip_img, conv4], mode='sum'))
op = Convolution2D(2, 3, 3, border_mode='same')(conv5)
for layer in base_model.layers:
layer.trainable = False
model = Model(input=base_model.input, output=op)
model.compile(optimizer='sgd', loss=custom_loss_fn)
디렉토리에 여러 개의 컬러 이미지가 있습니다. 입력 이미지는 세 번 쌓인 이미지 (224x224x3)의 그레이 스케일이어야하며 op은 그레이 스케일 (224x224x1)에 추가 할 수있는 이미지의 UV 평면 (224x224x2)이어야 YUV 이미지를 얻을 수 있습니다. 맞춤형 손실 기능은 원래 이미지의 UV 및 예측 UV에서 작동합니다.
어떻게 훈련합니까?