10
반복적으로 정점을 제거하여 그래프의 k-core을 계산하는 것만으로도 충분합니다. 그러나, 내 응용 프로그램의 경우 시작 그래프에 정점을 추가하고 전체 k 코어를 처음부터 다시 계산하지 않고도 업데이트 된 코어를 얻을 수 있기를 바랍니다. 이전 반복에서 수행 된 작업을 활용할 수있는 안정적인 알고리즘이 있습니까?증분 k- 코어 알고리즘
k- 코어는 클릭 찾기 알고리즘에서 전처리 단계로 사용됩니다. 크기가 5 인 모든 클록은 그래프의 4 코어 부분에 포함되도록 보장됩니다. 내 데이터 세트에서 4 코어는 전체 그래프보다 훨씬 작아서 무차별 적으로 강제로 처리 할 수 있습니다. 점을 점진적으로 추가하면 알고리즘이 가능한 한 작은 데이터 세트로 작동 할 수 있습니다. 내 꼭지점 세트는 무한하고 순서대로 (소수), 가장 낮은 번호의 도발에만 관심이 있습니다.
편집 : 그것에 대해 생각
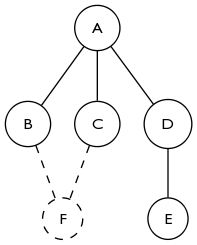
가 좀 더 루프의 생성을 감지, akappa의 답변에 따라 참으로 중요합니다. 아래의 그래프에서 2 코어는 F를 추가하기 전에 비어 있습니다. F를 추가해도 A의 차수는 변경되지 않지만 여전히 2 코어에 A가 추가됩니다. 모든 크기의 루프를 닫으면 모든 정점이 동시에 2 코어에 결합하게되는 것을 확인하기 위해 이것을 확장하는 것은 쉽습니다.
정점을 추가하면 임의의 거리에있는 정점의 중심부에 영향을 미칠 수 있지만, 최악의 경우에는 너무 많이 집중됩니다.